Empty-string URLs in HTML – A followup
Late last year, after spending 10 days tracking down a horrific bug, I posted, Empty image src can destroy your site. The post laid out a problem present in almost all modern browsers regarding empty string URLs in HTML. Empty-string URLs look like this:
<img src="">
<script src="">
<link rel="stylesheet" href="">Depending on the browser, one or more of these elements will actually cause another request to the server. Not just any request, though, a request to the containing page. That means the entire markup of your page is regenerated and served even though no one is actually viewing it. The linked post explains in detail why this is problematic, but suffice to say, these type of unexpected requests to your server can bring down high-traffic sites by unexpected increasing traffic or alternately can corrupt user state information.
Current state of browsers
As a quick summary of where we are today, here’s how the various browsers stock up:
- Internet Explorer through version 8 make a request for
<img src="">only. - Firefox 3 and earlier makes a request for all three of the patterns.
- Firefox 3.5 fixed the
<img src="'>case but not the others. - Safari 4 makes a request for all three patterns.
- Chrome 4 makes a request for all three patterns.
- Opera doesn’t make a request in any of these instances.
It’s not a pretty picture out there. But there has been movement since my last post.
Forward progress
Believing that this was the wrong behavior, I began contacting various browser vendors to ask if this behavior could be addressed. The most frequent response I received was that the browser was “following the standards” and shouldn’t be changed. I thought this was too dismissive and did some digging. The inconsistent treatment of empty-string URLs even within a single browser led me to believe that there was no specification governing this behavior. As it turned out, the specification to which everyone was referring was the URL specification (RFC 3986 – Uniform Resource Identifiers) and not HTML. While the URL specification does indicate that resolution for an empty string should result in the containing page, my argument was that this made no sense in the context of HTML.
HTML5
So in December, I posted a message to the WHAT-WG mailing list to see if I could get some consensus on this issue. After a lengthy discussion and a bunch of research, everyone ended up agreeing that this behavior was unexpected and should be changed. This month, changes were made to HTML5 specifically stating that empty-string URLs should not cause server requests for the following (complete diff):
<img src="">
<input type="image" src="">
<script src="">
<link rel="stylesheet" href="">
<embed src="">
<object data="">
<iframe src="">
<video src="">
<video poster="">
<audio src="">
<command icon="">
<html manifest="">
<source src="">Essentially, any tag that would result in the automatic download of an external resource will not make such a request if an empty-string URL is specified.
Thusfar, the Firefox team has agreed to make this update (see bug 531327). I filed a bug with the Chromium team (issue 38144) and also commented on a bug that was already filed at WebKit (bug 30303) and am waiting for updates (if a WebKit contributor would like to take this on, please do). Perhaps not surprisingly, I’ve had a little trouble pleading my case to Microsoft. I’ve not given up, but if you are or have a Microsoft contact that could help resolve this issue, please let me know.
YSlow
Since the empty-string URL issue really affects server performance, I asked the YSlow team if they could add in empty-string URL detection. Even though the issue with empty image URLs has been resolved in Firefox, it’s still present in other browsers, so YSlow’s flagging of this serious issue can help you avoid problems in other browsers.
In this initial release with the feature, there is a new non-default rule that you can turn on in a custom ruleset. To do so, click the Edit button next to the list of rulesets, check the box next to “Avoid empty src or href”. Click “Save ruleset as…” and type in a new name. Then, select your new ruleset from the dropdown box and click the “Run Test” button.
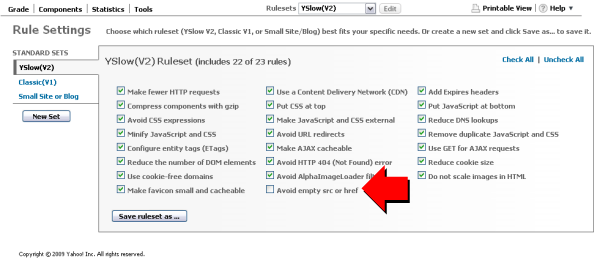
This new rule is under the “Server” group of rules. YSlow will correctly detect <img src=""> and <link rel="stylesheet" href=""> and give you an F if there are any instances of either of these patterns.
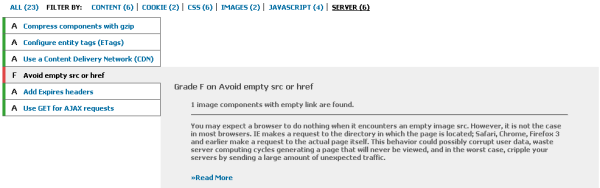
Note that due to a bug in YSlow, you’ll sometimes also get an A for this rule even if you do have one of the offending patterns present. This will be addressed soon.
Thanks
Things sometimes seem to move slowly on the Internet, but ultimately I believe things tend to get done correctly. We’re still likely at least a year away from never needing to worry about this issue again, and for that I need to thank a bunch of people:
- Jonas Sicking of Mozilla for suggesting that this issue be brought up on the WHAT-WG mailing list and for participating in the discussion.
- Simon Pieters of Opera and Maciej Stachowiak of WebKit for chiming in and agreeing that this behavior seemed broken.
- Ian Hickson for making the adjustments in HTML5 so that this issue can be put to rest.
- Stoyan Stefanov and the YSlow team for adding empty-string URL detection to YSlow.




